foundev.github.io
Lambda+ or Event Sourcing with TTLs
Some people are worried about the data volume that a strategy like Lambda+ or Event Sourcing implies. As a disclaimer, by giving up the historical data you have, you risk losing useful data layer and you lose the ability to have bi-temporal data or go back in time. However, if you still don’t care about that, please continue reading.
Transaction Log Lessons
If we think of Event Sourcing as a transaction log we can borrow some valuable lessons. How is it like a transaction log you ask?
- I have all updates
- I have all deletes
- I have all initial writes
- I can use it to replay and repair other parts of my data base (derived views)
Ok so it’s like a transaction log so what? We can borrow the idea of check points or a “known good state” to get us where we can safely apply a TTL to our events.
Checkpoints
Using Microsoft’s definition for checkpoints
A checkpoint creates a known good point from which the SQL Server Database Engine can start applying changes contained in the log during recovery after an unexpected shutdown or crash.
So to apply to our use case, a checkpoint will be represented by a rollup of all events that occurred before the date range of that rollup.
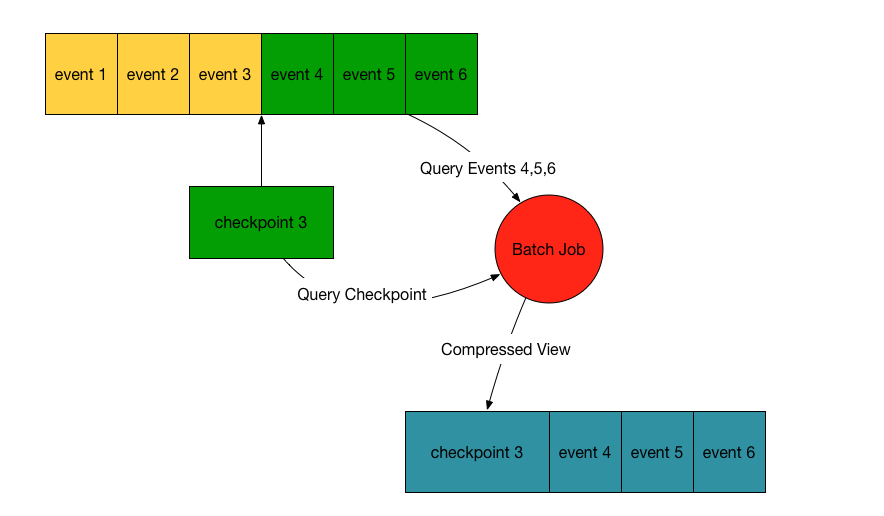
The writes that are after the checkpoint but before TTL will be ignored, and will not affect batch jobs to generate data.
Entity Checkpoints
Let’s take a look at an entity type rollup (the simple case)
CREATE TABLE my_keyspace.events ( bucket timestamp,
event_id timeuuid, entity_id uuid, attribute text,
value text, PRIMARY KEY( bucket, event_id,
entity_id, attribute ));
CREATE TABLE mykeyspace.checkpoints ( bucket timestamp,
entityId uuid, attribute text, value text,
PRIMARY KEY(bucket, entityId, attribute))
If we take this approach say for a user account, with 3 events, one where the user gets married:
INSERT INTO mykeyspace.checkpoints (bucket,
event_id, entity_id, attribute, value)
VALUES ('2014-01-10 11:00:00.000',
2d3c8090-5cab-11e5-885d-feff819cdc9f<strong>,
</strong>ebe46228-402c-4efe-b377-62472fb55684,
'First Name', 'Jane')
INSERT INTO mykeyspace.checkpoints (bucket,
event_id, entity_id, attribute, value)
VALUES ('2014-01-10 11:00:00.000',
<strong> </strong>a6a105d2-5cab-11e5-885d-feff819cdc9f,
2d3c8090-5cab-11e5-885d-feff819cdc9f,
'Last Name', 'Smith')
INSERT INTO mykeyspace.checkpoints (bucket,
event_id, entity_id, attribute, value)
VALUES ('2015-02-12 09:00:00.000',
8bc4046c-5cab-11e5-885d-feff819cdc9f,
2d3c8090-5cab-11e5-885d-feff819cdc9f, 'Last Name', 'Zuma')
The checkpoint for this same record would look like the following
INSERT INTO mykeyspace.checkpoints (bucket,
entityId, attribute, value) VALUES
( '2015-06-01 10:00:00',
8bc4046c-5cab-11e5-885d-feff819cdc9f,
'Last Name', 'Zuma' )
In this case you’ve lost the original data, so as long as you later do not need to get “initial last name” then you’re fine.
Aggregation Checkpoints
You could go also the really easy route and rely on your existing computed views.
CREATE TABLE mykeyspace.clicks_by_city
(city text, country text, clicks bigint,
PRIMARY KEY((city, country)) )
CREATE TABLE mykeyspace.batch_runs
( table_name text, newest_bucket_run_against timestamp,
PRIMARY KEY(table_name) )
Then it becomes easy enough to ignore all records older than that timestamp when rolling up later on.
Replay Caveats
Once you’ve chosen to ignore any events older than X you cannot safely replay them. You’ll have to blow away previous checkpoints and views and start over back to the point you replay and your replay will have to be complete.