foundev.github.io
Lambda+: Cassandra and Spark for Scalable Architecture
UPDATE: For some background on Spark Streaming and Cassandra please consult some of my previous blog post on the subject.
Many of you have heard of and a few of you may have used the Lambda Architecture. If you’ve not heard of it the name doesn’t communicate a lot. In short the Lambda Architecture has 3 primary components with a 2 pronged approach to analytics:
This is a very brief overview with some generalizations, so for those interested in the detail I suggest reading up more at http://lambda-architecture.net/.
Ok great so how does Cassandra & Spark fit in?
With Cassandra & Spark we can build something that achieves the same goals as the Lambda Architecture but more simply and with fewer moving pieces by combining your Speed Layer and your Batch Layer into a single data store running on Cassandra and utilizing Spark and Spark Streaming to have a single code base responsible for analytics and streaming. This paper will detail how to achieve this savings in complexity compared to the traditional Lambda Architecture.
Deployment Overview
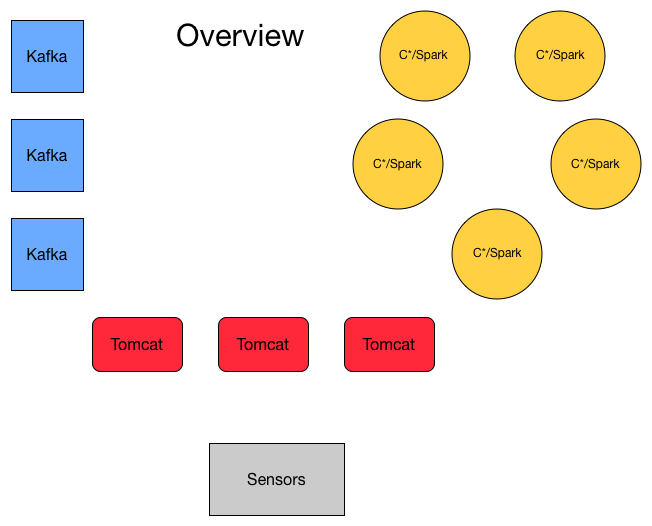 </div>
</div>
Schema
CREATE KEYSPACE lambda_plus WITH REPLICATION =
{ ‘class’:’NetworkTopologyStrategy’, ‘Analytics’:3 }
CREATE TABLE lambda_plus.records ( time_bucket ts,
sensor_id int, data double, ts timestamp, primary key(
time_bucket, sensor_id)); //populated by the Application Servers
CREATE TABLE lambda_plus.bucket_rollups
( time_bucket datetime, average_reading double,
max_reading double, min_reading double);
// populated by Spark Streaming and
//Spark Job and therefore populated every second
CREATE TABLE lambda_plus.sensor_rollups (sensor_id,
last_reading ts, average_reading double, max_reading double,
min_reading double);
// populated by Spark Job only and therefore
// stale for up to an hour
Application Components
Sensor Data Ingest
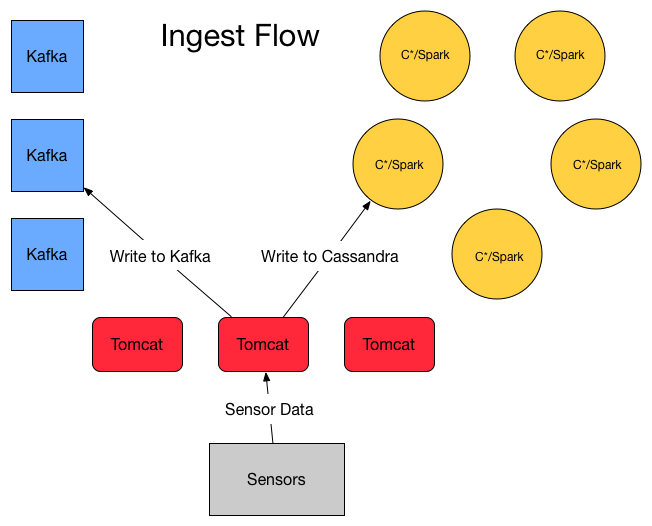 </div>
</div>
Sensors themselves submit an HTTP request to the application servers which then perform 2 functions:
- Submit a record to Kafka
- Submit a record directly into the lambda_plus.records table on a 100ms time bucket (failure handling for the 2 current writes is an exercise left to the reader and a paper in and of itself) to Cassandra.
Spark Streaming Job
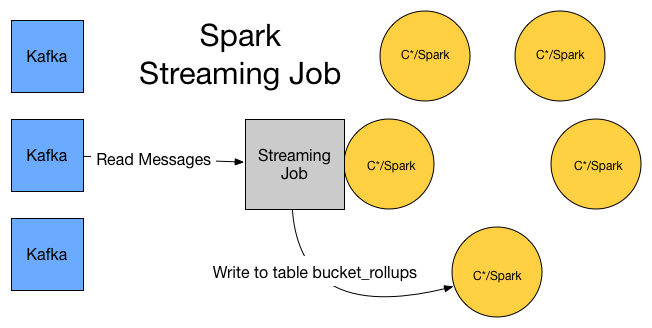 </div>
</div>
A Spark Streaming job will be running on the cluster every second. This will take messages from Kafka and aggregate the results and flush them to the lambda_plus.bucket_rollups table.
Spark Batch Job — Bucket Rollups
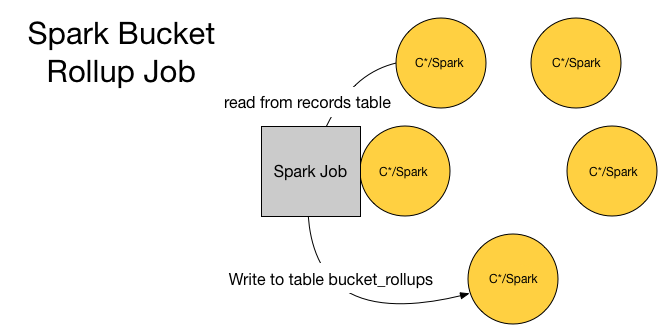 </div>
</div>
This will operate on every data row older than 5 minutes in the lambda_plus.records table (This is to allow for time series buckets to be totally complete and all retries to have been already sent by sensor data.). The role of this job is to correct any errors in the Spark Streaming Job that may have occurred due to message loss.
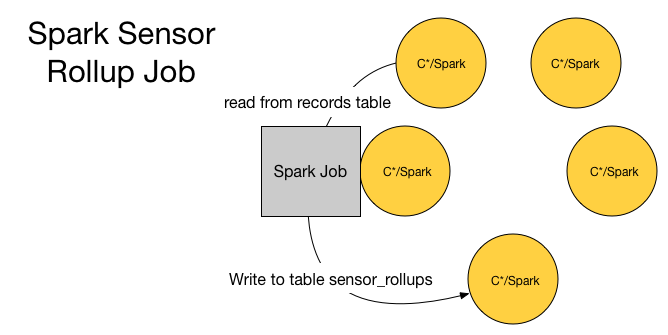
Spark Batch Job — Sensor Rollups
 </div>
</div>
This will operate on every data row older than 5 minutes in the lambda_plus.records table (This is to allow for time series buckets to be totally complete and all retries to have been already sent by sensor data.). This will take each sensor found and aggregate the results in lambda_plus.sensor_rollups. You’ll note this is not filled by the Spark Streaming Job as it would require a historical lookup, while this can be doable it can be expensive if there is a lot of historical data and may not be efficient. This is a classic design tradeoff, and one must decide how important really fresh data is.
Dashboard
The application servers driving the dashboard will be able to use pure CQL queries to get up to the second data for bucket rollups and 1 hour delayed data for sensor rollups. This provides low latency and high throughput for answering queries. Our dashboard is using Cassandra in the optimal fashion.
Lambda Architecture compared
Speed Layer
Identical between this architecture and Lambda. A lot of customers will use Spark and Cassandra for the traditional Speed Layer.
Batch Layer
Instead of writing to a separate database our Batch Layer will write directly to the same Speed Layer tables that are then served up by Cassandra. Contrast this with the traditional Lambda Architecture where the Batch Layer is using a different code base and a different database than the Speed Layer, I think you’ll agree the Lambda+ approach is much simpler.
Serving Layer
Can all be done out of Cassandra, instead of out of a Batch Layer database. This provides operational simplicity over the traditional Lambda Architecture and not only results in less servers but in less code complexity.
Conclusion
This approach will not only scale as you add more nodes and more data, it will allow you the best of several approaches at once and with the operational simplicity of a single data store.